Visual editing of semistructured documents on the web
Exploring patterns and approaches
—
A talk I gave at the International Conference for Educators in Visual Communication at the California Technical University in San Luis Obispo. It was great fun to be able to give a talk on a topic that has been following me for several years.
In this presentation I will discuss some of the possibilities but also the problems of editing structured content in a visual fashion. The goal of it all is to communicate the structure we want/need to the author of the content. We hope to do this by well established visual means like typography, color and the likes. Let’s begin with some personal background history which will clarify the problem we are trying to solve.
In one of my first jobs, I have worked for a series of law publications. Those magazines discussed recent decision of the Swiss Federal Courts to show their implications for future cases. The magazines had existed for some time already and the workflow was print first. Trying to change the workflow so we could publish the articles on the web too proved difficult. Not so much from a technical perspective but rather because the authors didn’t like the tools we asked them to use which were mostly forms.
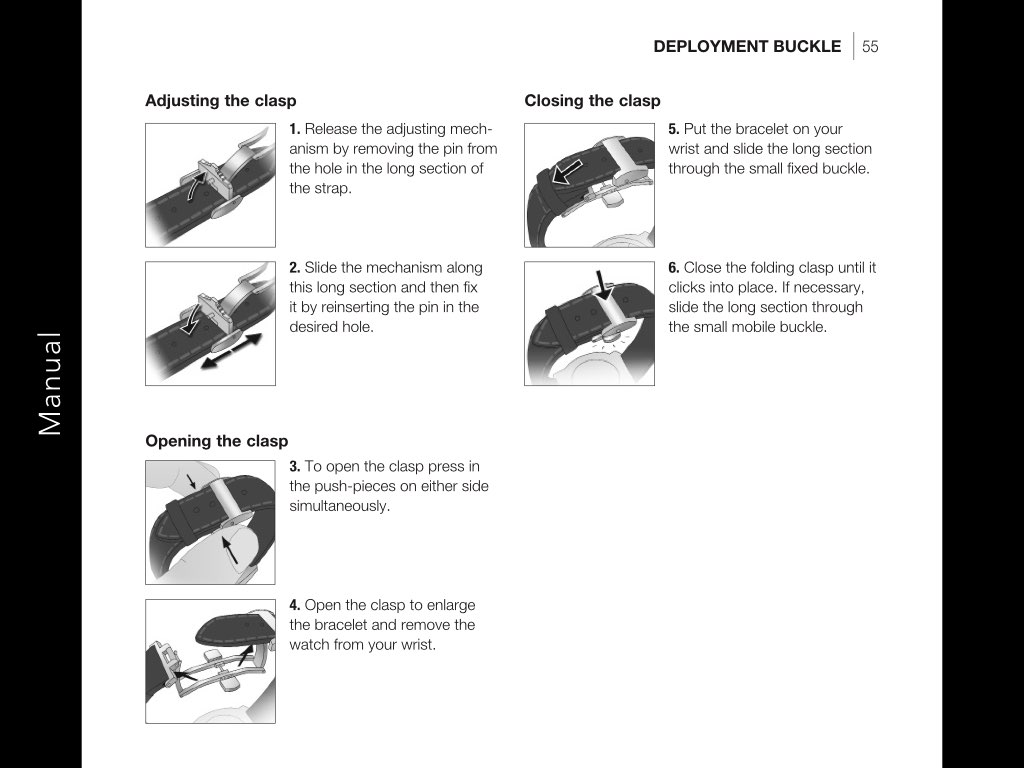
For my bachelor’s thesis I experienced the same problem all over again. We had these beautiful ideas of re-using content in multiple publications. This was especially intriguing because the client was an internationally active watchmaker. All their content was translated into 30 different languages. So reusing it would have resulted in tremendous savings. But equally, we didn’t have a tool which would allow untrained authors to produce well-structured and therefore reusable content.
For example, we have the step-by-step instructions of the manual. Many of those instructions are being reused and recombined for multiple models. But currently each of those copies is handled like a separate text.
Some editorial content was also reused in several places. The descriptions of the different materials employed in the watches for example. The content was very similar with slight variations from place to place. This led to many unnecessary retranslations of the same material.
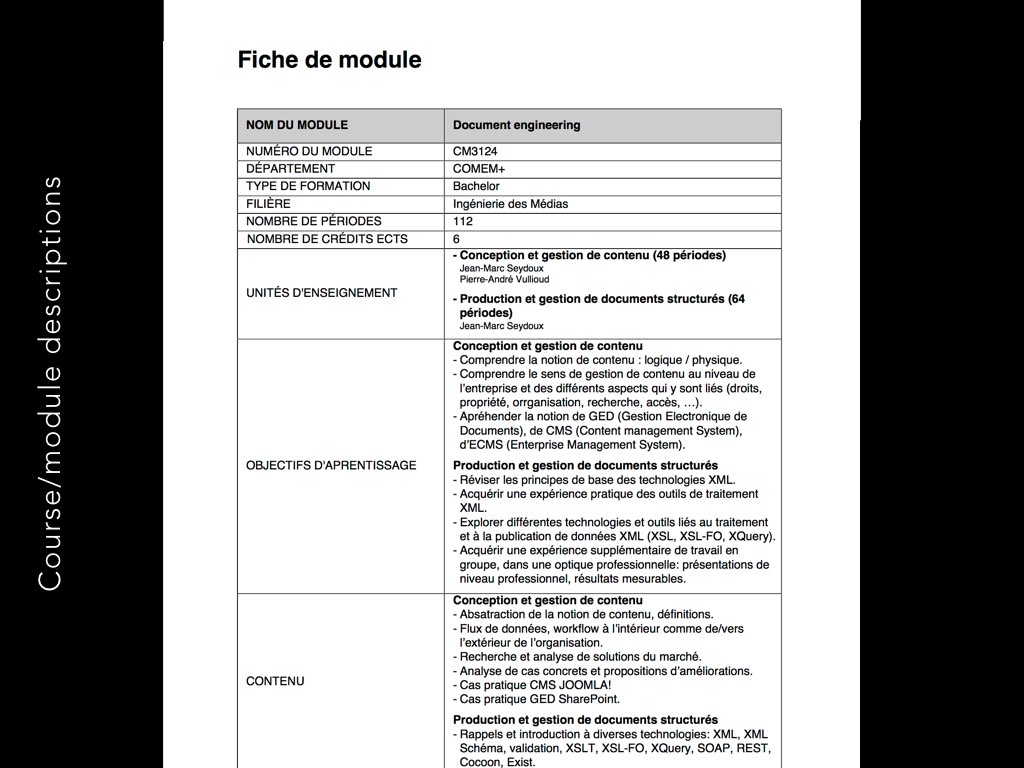
As a last example for our case, there are the course description at the University of Applied Sciences where I work. Those descriptions very highly structured and reused in several places. Still, the professors write them in Word because all the alternatives are worse. But are they?
First, let us define more clearly who we actually **target** with our solution. We decided to call them *novice users*. They are indeed novices when it comes to use our editing solution. And they should never need to become experts, that's the whole point. We want to avoid the need for training. At the same time, our targeted users are expert in their domain. Be it lawyers, watch sellers or professors.
The next step is to define the **type of content** we are working with. We decided to call them *documents*. Their particularity is that they can stand on their own and are usually created to be distributed as a whole. At the same time, they contain some structure which allows to compare multiple documents based on certain attributes. We could, for example, compare multiple articles based on their summaries. Or course descriptions based on the number or periods each course lasts.
We call this kind of content *semistructured*.
In order to understand how we should edit *semistructured content*, we'll try to understand the nature of semistructured content. It can be located between highly structured content and completely unstructured content. The main property of structured content is, that its structure can be defined beforehand. For example, when creating the schema of a database to store address book entries. On the other end of the spectrum, content and presentation are perfectly blended and create a unique ensemble. Semistructured content fills the spectrum between the extremes but always integrates both ideas in parts.
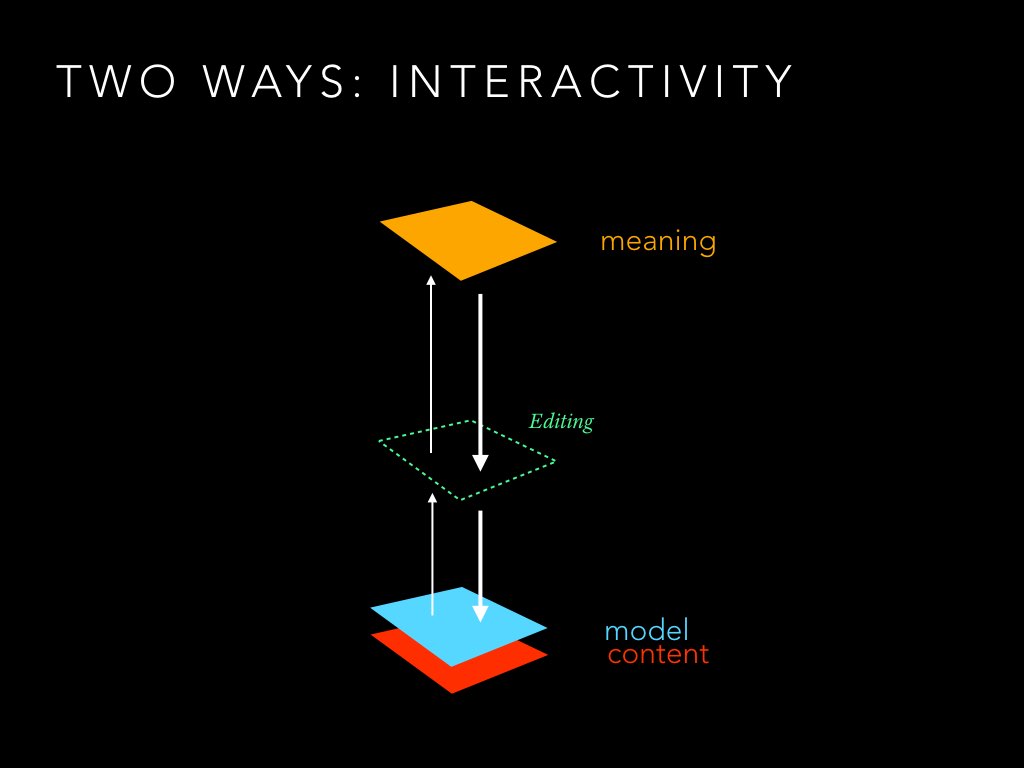
A document is therefore a mix of three things:
The content itself
A model which defines how the content should be understood
A presentation which defines how everything looks.
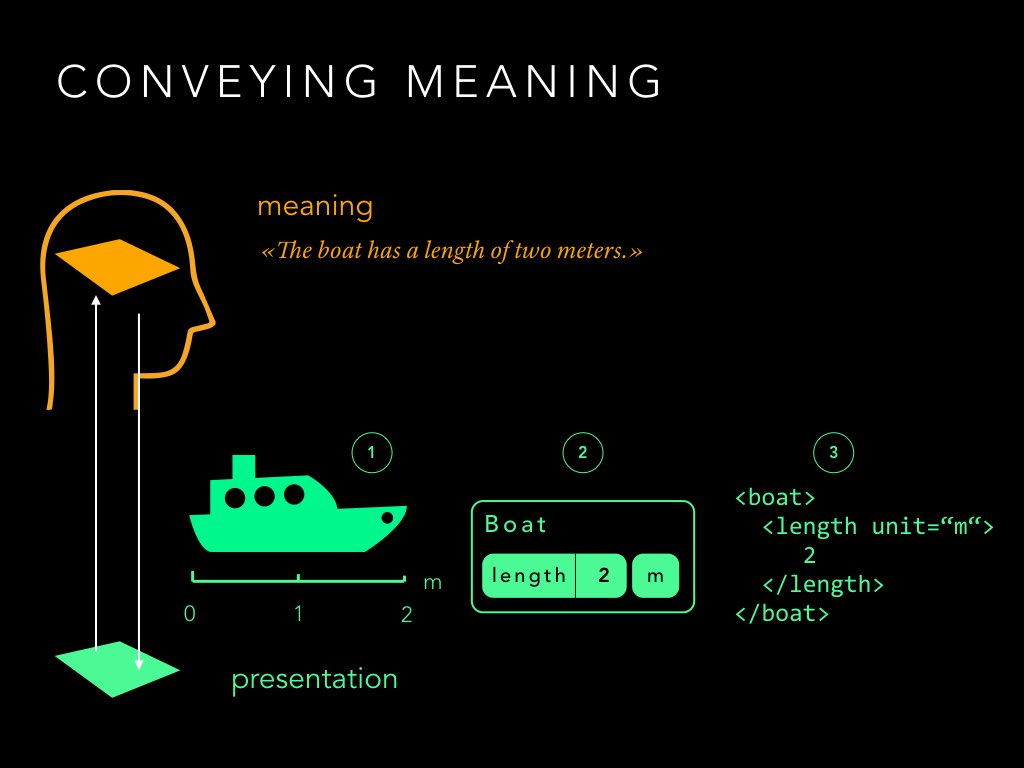
It is important to notice that with the same content and the same model, numerous presentations are possible. The length of aa boat can be presented in different ways as seen on the slide.
The role of the presentation layer is to convey the meaning of the content to the reader. Ideally it helps him understand the underlying model and the structure of the content. With this knowledge, the reader is well equipped to unpack the message and understand it in its proper context.
One example for this can be seen here. Even without understanding what the text says, the reader immediately understands that this represents at ticket. This is deduced because of formal conventions. He can even find out how high the entry fee is or at which date the event is going to take place. And that is just because the numbers are laid out in the right way. Be careful, this tool is pretty powerful.
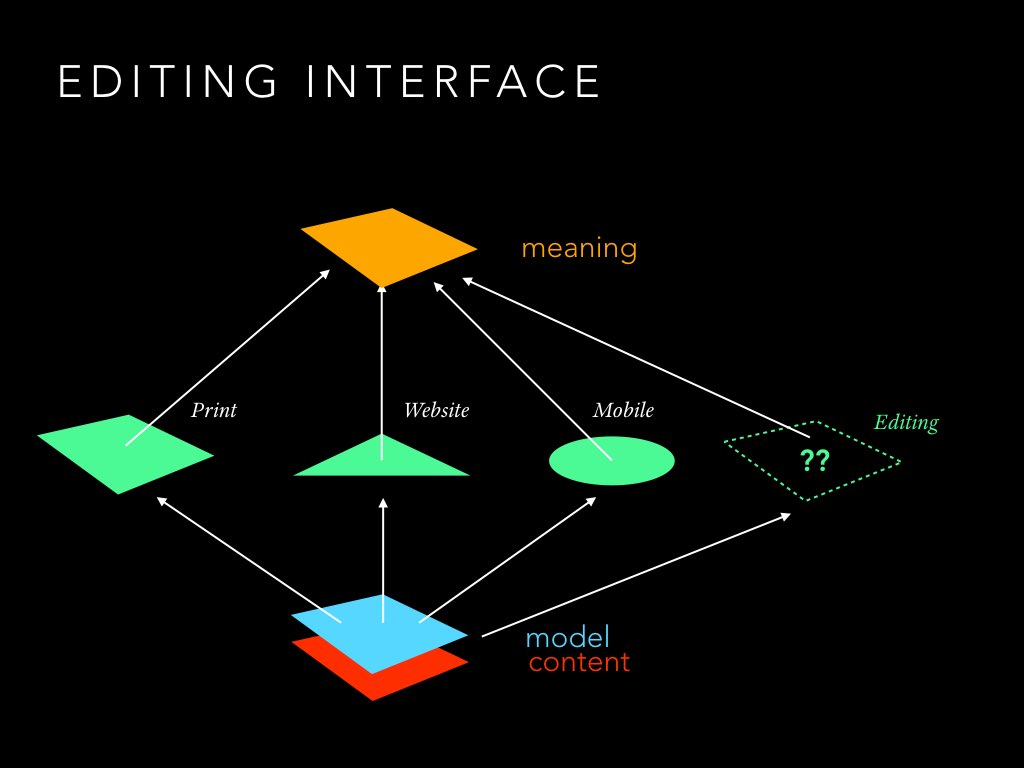
Let's get to the core of our argument. Why do we even need to have all this structure? We have been living happily without it for hundreds of years. We've also been living happily without iPhones or TVs for hundreds of years. The reality is that they are there and everyone has one. So we better deal with it. Different screen sizes demand different presentations of the content. That's what is called "Polypublishing" (or some other name depending on the time of the day and the phase of the moon). By simply applying different templates to our content, we can create multiple presentations of it. The template works on elements that are defined by the model. That's why we need it.
The question I was asking myself was then: When we have designers who are specialists in communicating meaning with visual codes. They already create all these templates for readers. Then we have authors who are not much more trained than normal readers. Why wouldn't we use the same means to communicate the model to them as to our readers? It basically just means one template more to do for the designer.
So what are the reasons and difficulties who have stopped us from doing so until now? For the designers, the main additional challenge is the interaction. Only in recent years has the field of interaction design gained traction and interest from younger designers. Traditionally, designers were used to work for more static environments. More interactive parts of the interface were therefore often left to be done completely by developers who just wanted it to work. We'll come back to this a little later.
Finally, we are able to define some minimal requirements. The two points are somewhat representative of the two mindsets involved in creating our imagined solution. On one hand, there is the developer who is mainly interested in the quality of the data he gets. That is because he knew that if he is not pushing this, it will result in a lot of work down the road. On the other hand, there is the designer who is the users advocate. His jobs is to understand the user and be his advocate.
The developer-mindset typically produces this data-centered form-interfaces. There is no visual hierarchy and the only way to tell different types of content apart is by the labels. It is pretty easy to create such an interface from an existing model. In many cases it can even be automated. Typically, most people despise filling out those forms almost as much as declaring their taxes.
Document centered interfaces are typically what a designer would create. This is your typical WYSIWYG-Interface. The author is empowered and can format the content in the way she wants. This is often indicative of their own internal model of the content. Unfortunately, with multiple authors there will usually little coherence between their internal models which they try to convey with the formatting. This results in many hours of manually normalizing the different models into one.
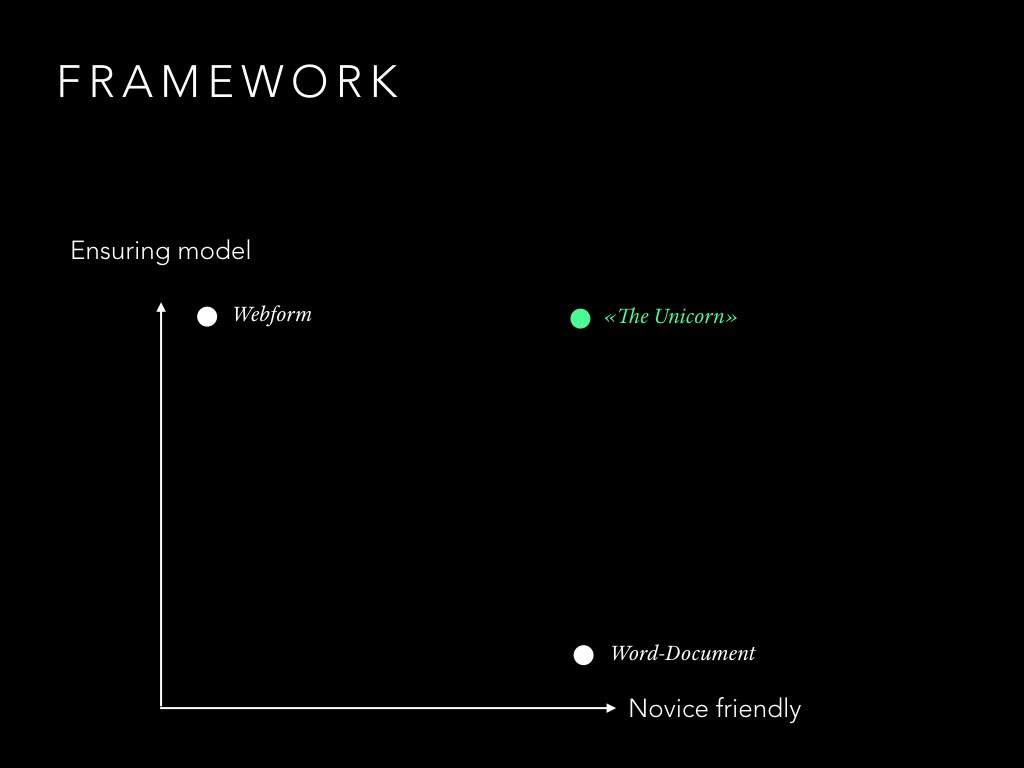
The interests seem to be conflicting then. But is it possible to have it both ways? In order to help us evaluate existing solutions, we build a framework which plots each requirement on one axis. How well can the model be enforced? And how user-friendly is the interface? The imaginary perfect solution is called, in good internet-speak, "The unicorn".
First, let's map two extremes. The web form can perfectly ensure a given data model while being a pretty awful experience. The Word document is universally liked by many people but doesn't impose any structural constraints.
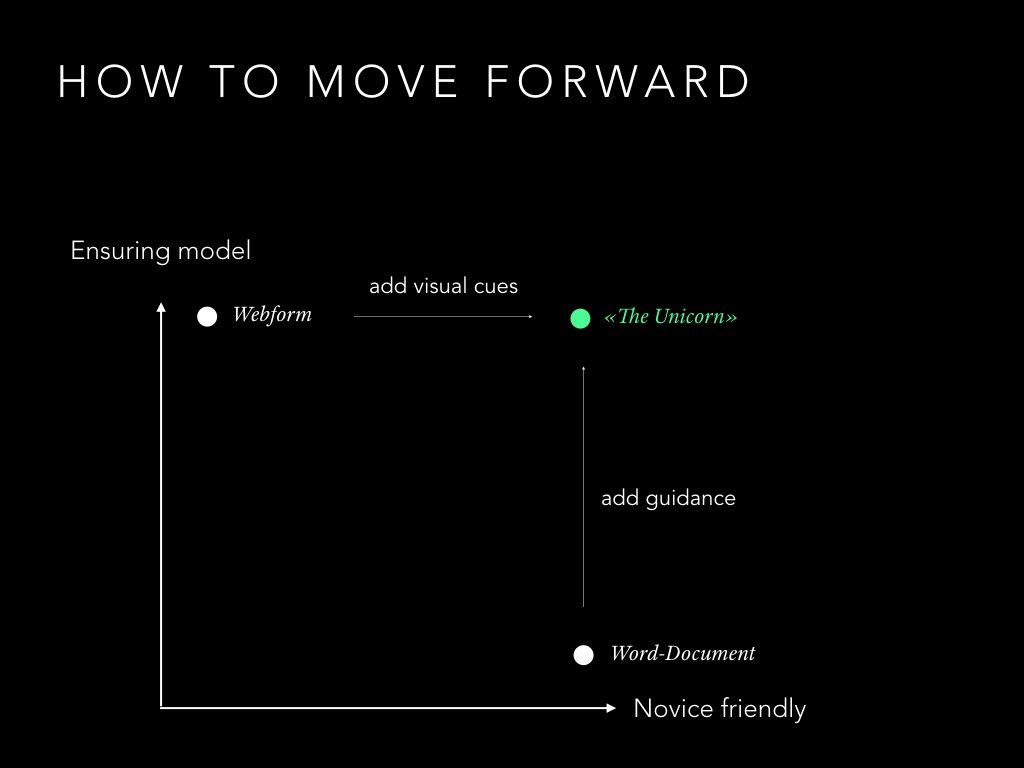
We could start from any of those two and move towards the Unicorn. For web forms, we should just let a designer work on it, adding visual cues and making it more pleasant to use. When starting from a Word document, we would need a way for the developer to add constraints like for example limiting the formatting options.
When mapping the solutions we investigated, an interesting pattern emerges. The data-centered interfaces are all open sourced while the others are commercial products. I wonder about the socio-economical reasons behind this. In any case, as a research project, it is important for us to start from an open sourced solution. This leaves us with the [AXEL-Editor](https://github.com/ssire/axel) as the most promising candidate.
AXEL is a JavaScript-library developed principally by [Stéphane Sire](https://people.epfl.ch/134506) and [Christine Vanoirbeek](https://people.epfl.ch/christine.vanoirbeek) at the EPFL university. It is based on their research on an XML-based language called [XTiger](http://www.w3.org/Amaya/Templates/XTiger-spec.html) which can be used to easily define editing interfaces for XML-documents. AXEL takes these XTiger-template and transforms them into an the necessary HTML and JS for editing. It also handles de- and reserialisation of the XML-data.
If you remember the course description at the beginning. This is the editing interface we created to produce those documents. It has a clear visual hierarchy which helps communicate the role and relationships of the different elements.
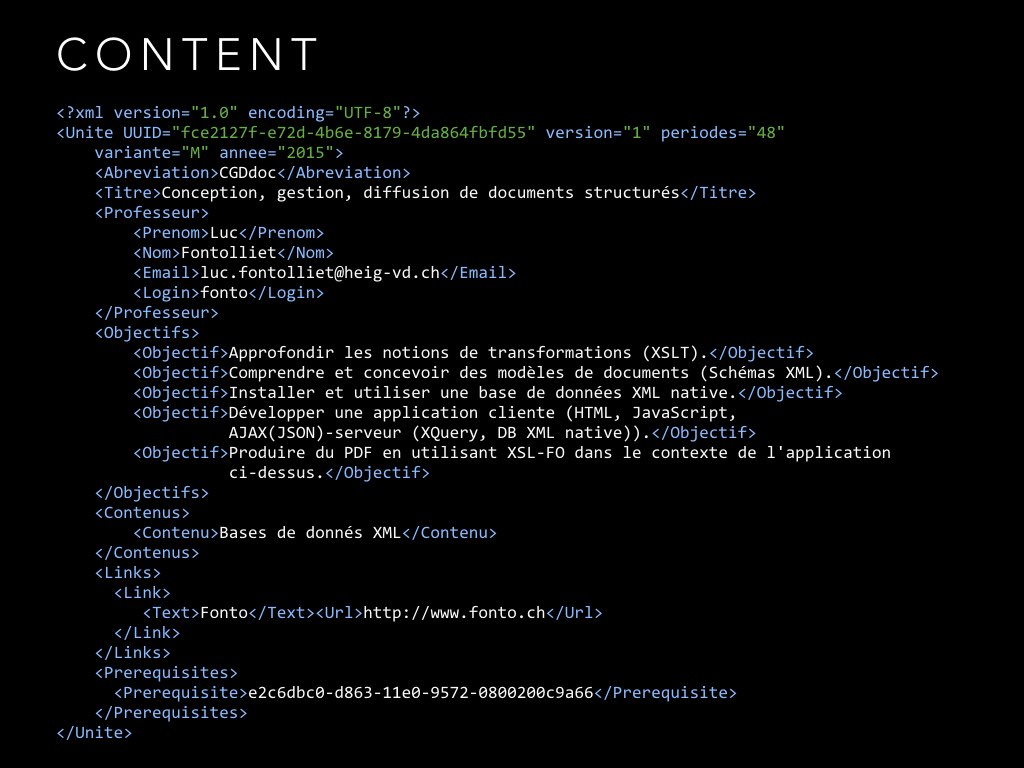
Behind the nice facade, there is a collection of pretty highly structured XML-documents which hold the content.
The structure or model of those documents is defined in an XML-Schema document. Note that there are attributes and elements like `annee` that will be invisible in the final presentation of the content. The editing interface needs to make them visible though for the author to be able to change this meta-data.
The final element of it is the XTiger-Template. For each element of the content, it defines how it should be presented, edited and mapped to XML. Here we see a basic mapping where we tell the editing interface to produce a widget to edit `content` and to map it to an element with name `Objectif`.
Because XTiger is namespaced XML it can be included in an XHTML-Document. With this, all the typical stack of web-technologies are available. Be it CSS for designing the interface or server-side languages to build and serve the template. Working well with web-technologies is clearly one of the strengths of the AXEL+XTiger combo.
AXEL is still pretty barebones. It manages some basic content types like images or links. But other projects will need other ways to input content. Tables for example or formulas. With its `types`-attribute, XTiger allows for extensibility by design. Widgets would therefore need to be created in AXEL to manage the wide variety of content types used in practice.
*Mixed content* is in a way the holy grail of document editing. It is hard for the interaction designer because he has to cope with messy things like selections and context. But it is also hard for the developer because he would need to have a better understanding of the content in order to intelligently propose or forbid certain markup-options. Those questions are left open for future study and reflection. Good hints can be found in many modern web-interfaces. One example being Facebook detecting and marking up names.